Arm发布全新CPU: Cortex X925、A725 和A520
随着半导体行业的不断发展,Arm 通过突破技术界限,为终端用户提供尖端解决方案,在核心和 IP 架构创新方面处于领先地位,尤其是在移动领域。2024 年,Arm 的年度战略进步重点是增强去年的 Armv9.2 架构,并带来新的变化。Arm 已重新打造品牌并重新制定战略,推出了客户端计算解决方案 (CSS:Client Compute Solutions),这是去年整体计算解决方案 (TSC2023) 平台的直接继任者。
Arm 还在将其最新的 IP 和 Cortex 核心设计(包括最大的 Cortex X925、中间的 Cortex A725 以及更新的较小 Cortex A520)过渡到更先进的 3 nm 工艺技术。Arm 承诺,与去年的设计相比,3 nm 工艺节点将提供前所未有的性能提升、能效和可扩展性改进,以及对其 Cortex 系列核心的新前端和后端改进。Arms 的新解决方案有望为下一代移动和 AI 应用程序提供支持,因为 Arm 及其完整的 AArch64 64 位指令执行和面向移动和笔记本电脑的解决方案方法有望重新定义最终用户对 Arm 产品上的 Android 和 Windows 的期望。
Arm 客户端计算解决方案 (CSS):CSS 是新的 TCS
客户端计算解决方案 (CSS) 的推出标志着 Arm 战略的一个重要里程碑,该战略旨在为合作伙伴提供全面而全面的计算解决方案,供其在新一年的移动设备周期中实施。CSS 是一个综合平台,集成了硬件、软件和工具,以优化客户端设备的性能和效率。它旨在为各种设备(从智能手机和平板电脑到笔记本电脑甚至台式电脑)提供无缝的计算体验。
Armv9.2 架构于去年推出,代表着 Arm 路线图向前迈出了重要一步。不过,今年,Arm 将在前代产品成功的基础上,引入一系列新功能和改进。改进后的 Armv9.2 系列的主要亮点之一是使用增强的安全功能,包括内存标记扩展 (MTE:memory tagging extensions ) 和机密计算架构 (CCA:confidential compute architecture)。这些功能可针对各种安全威胁提供强大的保护,使设备更加安全。
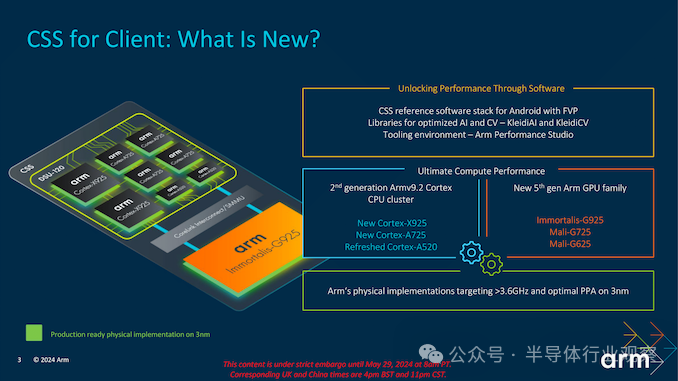
CSS 利用为 2024 年设计的最新 Armv9.2 内核,包括高性能 Cortex X925、均衡的 Cortex A725 以及节能且更新的 Cortex A520。这些内核与 Arm 的全新 Immortalis G925 GPU 相得益彰,旨在以移动设备大小的封装提供卓越的图形性能和效率。这些组件共同构成了现在所谓的 CSS 平台的基础,该平台旨在为移动领域的现代设备提供强大而多功能的计算解决方案。
CSS 的主要特点之一是其强大的可扩展性,可适应不同的市场,例如移动设备和笔记本电脑。该平台旨在适应不同的设备外形和性能要求,适合多种任务和应用。无论是高端游戏、专业内容创作还是日常生产力任务,CSS 都可以根据各种用例的需求进行定制。
Arm 的客户端计算解决方案 (CSS) 平台代表着 IP 设计和架构改进方面迈出了重要一步,在性能和效率方面提供了多项重大改进。随着第二代 Armv9.2 Cortex CPU 集群的推出,包括新的 Cortex-X925(大)、Cortex-A725(中)和更新的 Cortex-A520(小)内核,CSS 平台旨在授权给合作伙伴时提供极致的移动计算性能。

此外,CSS 平台还包括适用于 Android 的全面参考软件堆栈、由新的 Arm 计算机视觉库(KleidiAI 和 KleidiCV)支持的优化 AI,以及通过 Arm Performance Studio 提供的强大工具环境。这种典型的整体方法可确保 Arm 的物理实现达到 3.6 GHz 以上的速度,并在 3 nm 节点上提供最佳的功率、性能和面积 (PPA) 指标。谈到 3 nm 模式,Arm 表示台积电和三星 3 nm 是其 CSS 核心集群的主要选择,尽管最有可能的是与台积电一起获得晶圆厂分配的情况,因为我们不确定是否有人会使用三星而不是台积电。
除了安全性增强之外,基于 3 nm 的 Armv9.2 还承诺大幅提升性能,尤其是新的大核心 Cortex X925,Arm 认为它是移动领域的新 IPC 之王。该架构已针对更高的时钟速度和更高的效率进行了优化,从而可以提供更高的每瓦计算能力。这是通过多项架构创新实现的,包括更宽的执行管道、改进的分支预测和增强的乱序执行功能。这些增强功能提高了内核的每周期指令数 (IPC),确保它们可以轻松处理最苛刻的工作负载。
过渡到 3 纳米工艺技术
转向 3 纳米工艺技术代表着半导体制造的重大飞跃,在性能、功耗和芯片密度方面均有显著改善。这一转变使 Arm 能够提供更强大、更高效的处理器,能够高效处理最苛刻的应用程序。
3 nm 工艺的主要优势之一是它能够在更小的面积内封装更多晶体管,从而提高性能并降低功耗。这对于移动和便携式设备至关重要,因为电池寿命和热管理是关键考虑因素。3 nm 工艺还使 Arm 能够在 Cortex X925 内核上提高时钟速度,确切地说最高可达 3.8 GHz。这可以实现更快、响应更快的计算体验,并将整体 IPC 性能推向超越现有水平。

Arm 声称,更新后的 Armv9.2 架构、全新 CSS 平台以及 3 纳米制程技术的结合,旨在全面提升性能和效率。从理论上讲,这应该能够为所有类型的设备实现其参考 CPU 核心集群设计,现在两个 Cortex X 核心已成为常态,而去年的参考设计只有一个。Arm 进行并展示的基准测试和实际测试(不应全盘接受)显示,单线程和多线程性能都有了显著提升,使得这些新解决方案成为各种应用的理想选择。Arm 甚至宣称,其最大核心 Cortex X925 在单线程 IPC 方面处于领先地位,超越了英特尔和 AMD 的产品,这是一个大胆的说法。
至于电源效率,新内核旨在提供更高的每瓦计算能力,从而降低能耗并延长电池寿命。这对于移动设备来说尤其重要,因为用户需要更长的电池寿命,同时又不影响性能。电源效率的提高还意味着更好的热管理,确保设备即使在繁重的工作负载下也能保持凉爽和响应迅速。

除了性能和效率的提升,新解决方案还带来了增强的安全性和AI功能。Armv9.2架构的内存标记扩展(MTE)和机密计算架构(CCA)可针对各种安全威胁提供强大的保护,确保数据和应用程序的安全。
新内核和 GPU 增强的 AI 功能也值得关注。随着 AI 在现代应用中的重要性日益提高,新解决方案旨在加速 AI 工作负载,提供更快、更高效的 AI 处理。这是通过专用的 AI 加速器和优化来实现的,这些加速器和优化充分利用了新架构和工艺技术的潜力。

工艺技术向 3 nm 迁移为半导体制造带来了许多机遇和挑战。对于软 IP,更大、更复杂的微架构需要更强的电压调节和缓解功能,以确保稳定性和性能。关键目标是优化目标节点上的正确 PPA(功率、性能、面积)。对于物理 IP,工艺复杂性带来了自身的挑战,包括扩展限制和支持更宽动态电压和频率缩放 (DVFS) 频谱的要求。此外,在极端功率密度下,这应该可以缓解热问题,并确保设备高效运行,这在移动设备中非常重要
为了应对这些挑战,Arm 全面审视 RTL 和物理实现的共同开发。这确保了其计算 IP 能够满足性能预期,同时克服先进工艺技术的挑战。
Armv9.2、CSS 和 3 nm 技术的进步为各种应用开辟了新的可能性,包括开发人员访问新的 Arm Kleidi 库。在移动领域,这些解决方案使更强大、更高效的智能手机和平板电脑能够处理复杂的任务,例如 AI 驱动的摄影、游戏和生产力。
新的解决方案以便携式外形尺寸为 PC 市场提供台式机级性能,使其成为笔记本电脑和二合一设备的理想选择。改进的性能和效率也有利于专业内容创作,从而实现更快的渲染、编辑和多任务处理。

在人工智能和机器学习领域,新解决方案提供了高级人工智能应用所需的计算能力,从自然语言处理和计算机视觉到自主系统和机器人技术。增强的人工智能功能可确保这些应用程序高效运行,从而提供更快、更准确的结果。
随着 Arm 不断突破半导体技术的界限,专注于增强 Armv9.2 架构、推出 CSS 平台以及过渡到 3 nm 工艺技术标志着向前迈出了重要一步。这些进步大大提高了性能、能效和安全性,使新一代设备能够轻松处理最苛刻的应用程序。
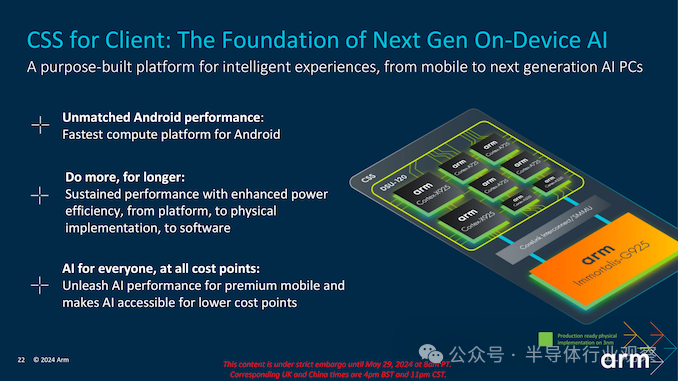
结合这些技术,我们能够提供强大且多功能的计算解决方案,该解决方案可以扩展到不同的设备外形和用例。无论是高端游戏、专业内容创作还是日常生产力任务,Arm 的最新解决方案都旨在提供最佳的计算体验。
好的硬件得益于好的软件
Arm 硬件的进步得益于一个复杂的软件生态系统,该生态系统旨在充分发挥其处理器的潜力。这个生态系统的核心是新的 Kleidi 库,它在优化人工智能 (AI) 和基于计算机的应用程序方面发挥着至关重要的作用。这些库为开发人员提供了量身定制的工具,以最大限度地提高 Arm 最新内核的性能和效率。

KleidiAI 是专注于加速 AI 工作负载的关键组件。它包括一套针对 Arm 架构优化的全面计算内核,能够高效执行各种 AI 任务,例如机器学习、自然语言处理和数据分析。通过为常见的 AI 操作提供高度优化的例程,KleidiAI 可让开发人员在保持能源效率的同时实现显着的性能提升。随着 AI 应用在移动设备、智能家居系统和工业自动化中变得越来越普遍,这一点变得越来越重要。
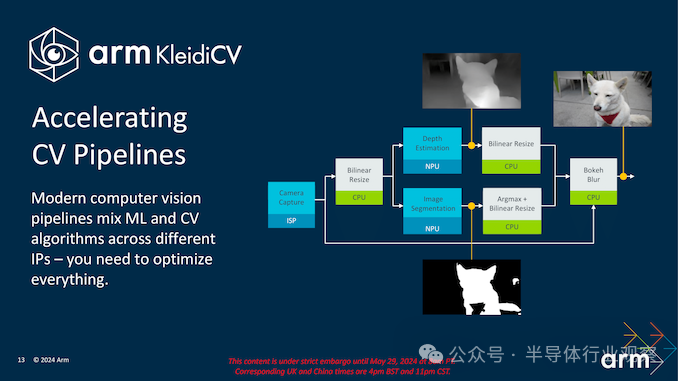
另一方面,KleidiCV 则针对计算机视觉工作负载。该库为图像处理、对象检测和场景识别等任务提供了优化的功能。将 KleidiCV 与 Arm 的架构集成可确保应用程序能够快速高效地处理视觉数据,使其成为增强现实、自动驾驶汽车和智能监控系统的理想选择。通过利用这些优化的库,开发人员可以构建在基于 Arm 的硬件上流畅运行的复杂应用程序,充分利用 3 nm 工艺技术带来的性能和能效改进。
除了 Kleidi 库之外,Arm 还提供了一套强大的开发工具和平台。客户端计算解决方案 (CSS) 平台包括参考软件堆栈和性能优化工具,如 Arm Performance Studio,它提供有关应用程序性能的详细见解,并帮助开发人员微调其软件以实现最高效率。这个全面的支持系统确保开发人员能够快速有效地将创新应用程序推向市场,充分利用 Arm 最新的架构进步。
在接下来的几页中,我们将分解 Arm 在其 2024 CPU 集群中的改进,包括新的 Cortex X925 和 Cortex A725 内核以及使用最小内核 Cortex A520 所做的改进。
Arm Cortex X925:引领单线程 IPC 的发展
Arm Cortex-X925 代号为“Black Hawk”,Arm 宣称,它处于单线程每时钟指令 (IPC) 性能的最前沿,至少从 Arm 的说法来看,它在很大程度上为提高性能和效率奠定了基础。该核心是 Arm 转向 3 nm 工艺节点的关键部分,并与第二代 Armv9.2 架构无缝集成。如果 Arms 的说法属实,那么 Cortex X925 将成为高性能移动计算领域的领导者,也是 Arm 及其对高效 PPA 的关注是 Arm 2024 CPU 核心集群驱动力的一个例子。

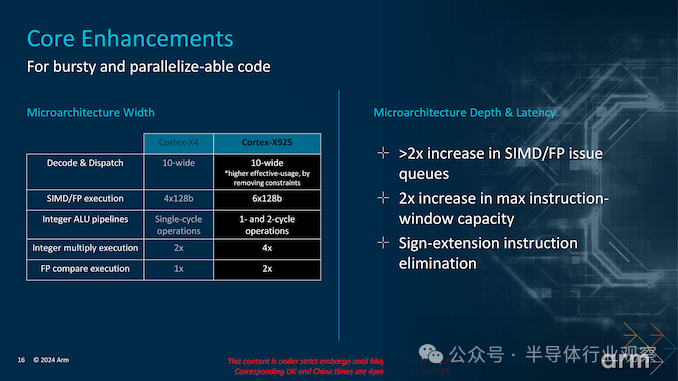
Cortex-X925 的架构改进旨在最大程度地提高 IPC。其突出特点之一是 10 宽的解码和调度宽度,大大增加了每个周期处理的指令数量。这一增强功能使内核能够同时执行更多指令,从而提高执行单元的利用率和整体吞吐量。
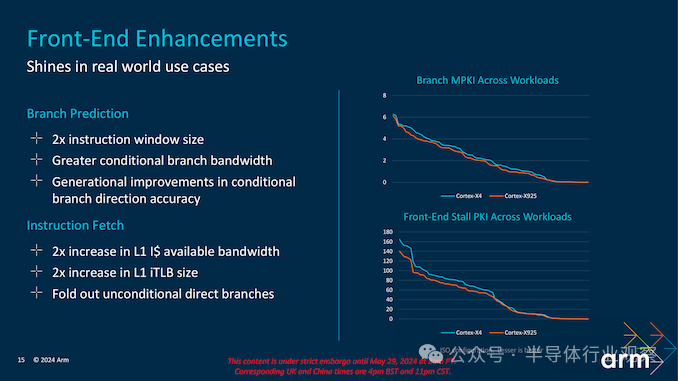
Arm 将指令窗口大小增加了一倍,以支持这种宽指令路径,从而允许在任意给定时间执行更多指令。这减少了停顿并提高了执行管道的效率。此外,该内核的 L1 指令缓存 (I$) 带宽增加了 2 倍,L1 指令转换后备缓冲区 (TLB) 大小也增加了类似倍数。这些增强功能确保内核可以快速获取和解码指令,从而最大限度地减少延迟并最大限度地提高性能。
Cortex-X925 还具有高度先进的分支预测单元,可减少错误预测的分支数量。通过采用折叠式无条件直接分支等技术,Arm 消除了多个架构障碍,从而实现了更精简、更高效的执行路径。这可以减少管道刷新次数并提高持续 IPC 水平。
Arm Cortex-X925 的前端展示了设计中的大量改进,包括提高指令吞吐量和减少延迟。这些改进的核心是 10 宽的解码和调度宽度,与以前的架构相比,这使内核能够在每个周期处理更多指令。这种宽指令路径增加了指令处理的并行性,使内核能够同时执行更多任务。
此外,Cortex-X925 的指令窗口大小增加了一倍,可容纳更多指令并最大限度地减少流水线停顿。L1 指令缓存 (I$) 带宽也增加了 2 倍,同时 L1 指令转换后备缓冲区 (iTLB) 大小也进行了类似的扩展。这些增强功能确保内核能够快速获取和解码指令,从而显著减少获取瓶颈并提高整体性能。
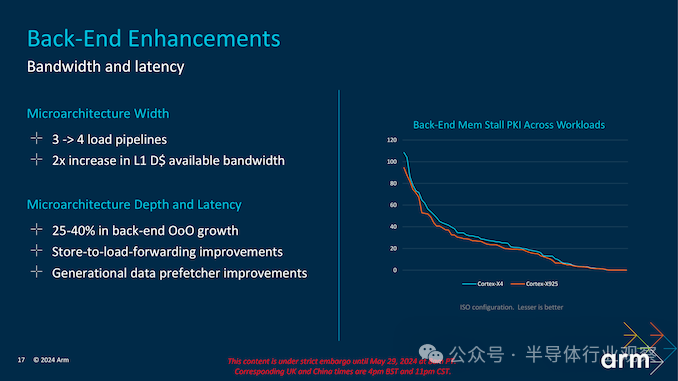
Cortex-X925 后端的乱序 (OoO) 执行能力显著提升,增幅达 25-40%。这一提升使内核能够更灵活、更高效地执行指令,从而减少空闲时间并提高整体性能。此外,内核的寄存器文件结构也得到了增强,增加了重新排序缓冲区大小和指令发出队列,最终有助于更顺畅、更快速地执行指令。
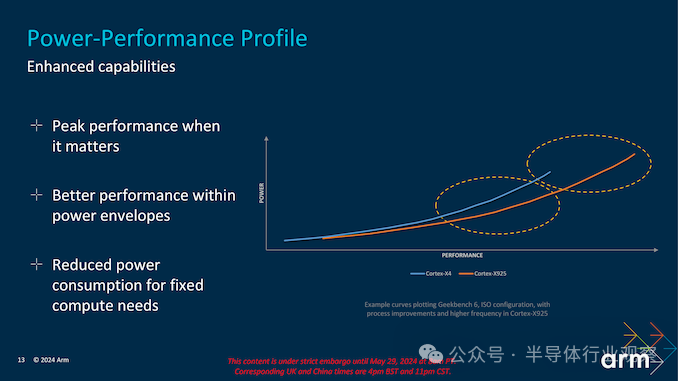
尽管性能出色,Cortex-X925 的设计也注重节能。3 nm 工艺技术至关重要,可实现比前几代产品更好的节能效果。内核的设计包括动态电压和频率调节 (DVFS) 等功能,可根据工作负载调整功率和性能水平。这可确保高效利用能源,延长电池寿命并减少热量输出。
Cortex-X925 还集成了先进的电源管理功能,例如每核 DVFS 和改进的电压调节。这些功能有助于更有效地管理功耗,确保内核在不影响能效的情况下提供高性能。这种平衡对于需要持续性能和长电池寿命的移动设备尤其有益。
Cortex-X925 还针对基于 AI 的工作负载进行了设计和优化,具有专用的 AI 加速器和软件优化,可提高 AI 处理效率。凭借高达 80 TOPS(每秒万亿次操作),该内核可以处理从自然语言处理到计算机视觉的复杂 AI 任务。这些功能得到了 Arm 的 Kleidi AI 和 Kleidi CV 库的进一步支持,这些库为开发人员提供了构建高级 AI 应用程序所需的工具。
有趣的是,Arm 本身并未涉足 NPU 或 AI 加速器领域。相反,它允许其合作伙伴(如联发科)整合自己的产品,以确保核心集群能够提供必要的支持和集成功能。凭借其参考软件堆栈和优化库,CSS 平台为开发人员提供了坚实的基础。全面的 Arm Performance Studio 提供了先进的工具环境,可帮助开发人员针对新架构优化其应用程序。
CSS 平台通过其重新焕发活力的 Windows on Arm OS 与 Android、Linux 变体和 Windows 等操作系统集成,确保了广泛的兼容性和易于开发。这种跨操作系统支持使开发人员能够快速高效地构建利用 Cortex-X925 功能的应用程序,以及整个更新的 Armv9.2 核心集群,这不仅可以加快上市时间,还可以确保跨多种设备的兼容性。
Arm Cortex A725:中核效率的提升
Arm Cortex-A725 旨在平衡性能和能效,是第二代 Armv9.2 架构的关键组件。它定位为中端内核,与高性能 Cortex-X925 相得益彰,为日常计算任务提供强大的功能,同时保持能效。该内核特别针对需要稳定性能但又不需要顶级内核高功耗的设备,例如智能手机、平板电脑和笔记本电脑。

Cortex-A725 在其前身 Cortex-A720 的成功基础上进行了多项关键架构改进。其中一项重大改进是增加了指令发布队列和扩展了重新排序缓冲区,这使得内核能够同时处理更多指令并乱序执行这些指令以提高效率。乱序执行窗口大小的增加使 Cortex-A725 能够更好地利用其执行单元,从而更顺畅、更快地处理复杂的工作负载。
该内核还受益于新的 1MB L2 缓存配置,可更快地访问常用数据和指令。这种更大的缓存大小旨在减少延迟并提高性能,特别是对于需要快速数据检索的应用程序。此外,Cortex-A725 的寄存器文件结构也得到了增强,进一步简化了数据处理并减少了瓶颈。
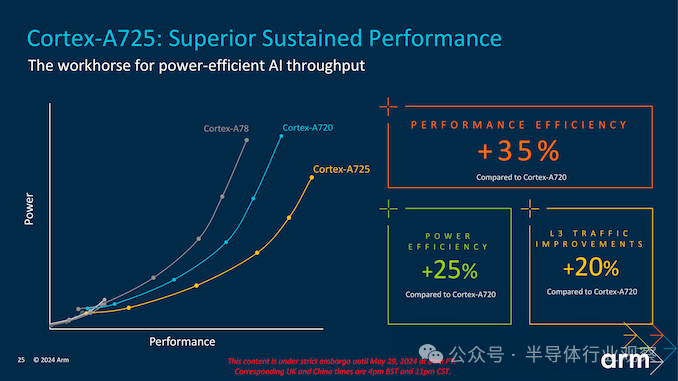
能效是 Cortex-A725 设计的一个关键方面。随着领先的 2024 Cortex 芯片预计将采用台积电等公司最新推出的 3nm 工艺技术制造,这些节点的改进性能能够推动能效的大幅提升,而 Arm 在 A725 中也大量采用了这一点。总体而言,Arm 宣称 A725 与前几代产品相比可显著节省电量。与 Cortex-A720 相比,Cortex-A725 的能效提高了 25%(L3 流量减少了 20%),使其成为需要长电池寿命的移动设备的理想选择。

该内核还具有先进的电源管理功能,包括动态电压和频率调节 (DVFS) 和half-slice断电模式。这些功能允许 Cortex-A725 根据当前工作负载调整其功耗,确保高效利用能源而不牺牲性能。
Arm Cortex A520:相同的 2023 核心,针对 3 nm 进行了优化
Arm Cortex-A520 在架构上并没有什么不同,与去年推出的 TCS2023 相比也没有变化。相反,它针对最新的 3 nm 工艺技术进行了优化,提高了效率和性能。该内核是第二代 Armv9.2 架构的一部分,可为移动和嵌入式设备中的日常任务提供一些额外的计算能力,同时保持峰值能效并降低 Arm 最小内核的预期功耗。
这些架构调整确保 Cortex-A520 可以最大限度地发挥 3 nm 工艺的潜力,实现更高的晶体管密度和更好的整体性能,而无需对其基本设计进行任何重大更改。
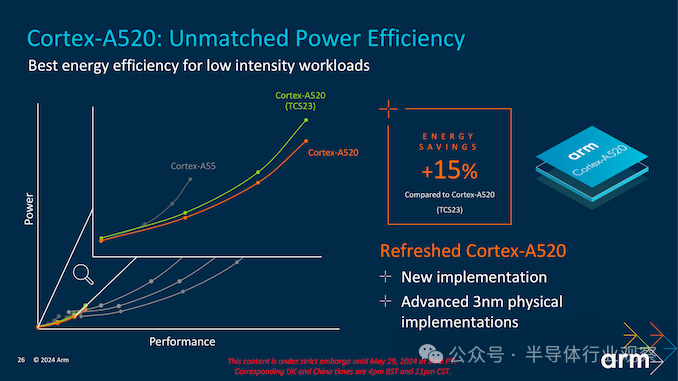
与 Cortex-A520 (TCS23) 相比,Cortex-A520 的节能效果显著,达到 15%。这一改进对于电池续航时间较长的设备(如智能手机和物联网 (IoT) 设备)至关重要。通过优化功耗,Cortex-A520 可确保高效性能,同时又不影响能耗。
上图清晰地说明了 Cortex-A520 与其前代产品 Cortex-A55 和之前的 Cortex-A520 (TCS23) 相比的功率和性能关系。专为 3 nm 设计的最新 Cortex-A520 显著提高了各个性能级别的功率效率。这意味着 Cortex-A520 在给定性能点上消耗的功率显著降低,表明 Arm 致力于在 2024 年的核心集群中提供性能提升,并专注于从功率角度对三个 Cortex 核心中最小的一个进行改进。
2024 年推进 3 纳米技术
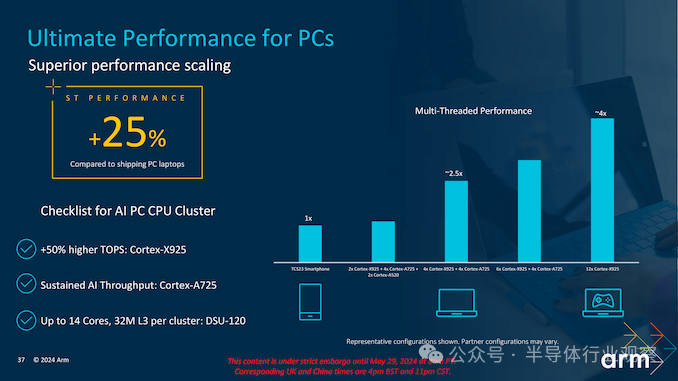
总体而言,Arm 面向客户端 PC 的 CSS 依赖于两个超高性能 Arm Cortex-X925 通用内核(每个内核高达 3MB L2 缓存,时钟频率超过 3.60 GHz,支持 SVE、SVE2)、四个高性能 Cortex-A725 内核、两个节能 Cortex-A520 内核和一个 Immortalis-G925 图形处理器。Arm 最新的 CSS 最多可支持 14 个 CPU 内核。CSS 是一种可用于生产的物理实现,可在 3nm 工艺技术上制造(可能是台积电的 N3E——尽管这只是猜测)。
Arm CSS 实现的实际规格可能会由处理器供应商更改以满足其性能和功率目标,但 Arm 用于性能评估的 FPGA 包括 Cortex-X925 内核(2 MB L2,3.80 GHz)、16MB L3、32MB 系统级缓存、2 GHz 的 DSU 和 LPDDR5X-8533 内存。
Arm 客户业务线高级副总裁兼总经理 Chris Bergey 表示:“我们现在在 Arm、CPU 和 GPU 上提供物理实现,使构建和部署基于 Arm 的解决方案变得更加容易,并且不会留下任何意外,从而实现新的性能点和计算能力,并帮助加快产品上市时间。”
“Arm 正在提供更多价值,与领先的代工合作伙伴合作,针对新的 3nm 工艺节点优化整个堆栈。这使我们能够以物理形式提供 IP。客户端 CSS 将物理实现与 Armv9 架构在 AI 方面的优势结合在一起。” Bergey说。
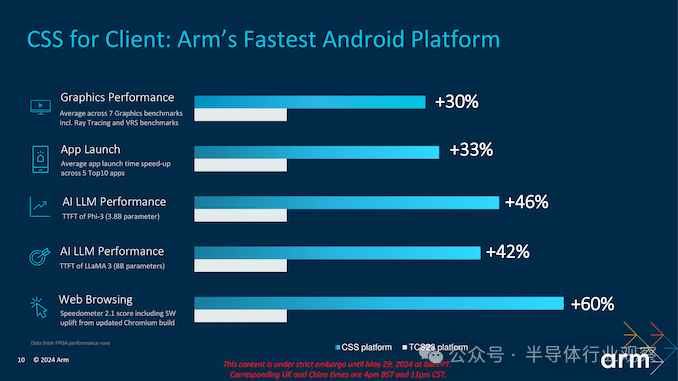
Arm 表示,Geekbench 6 单核得分与 TCS23 相比,Cortex-X925 CPU 的峰值性能提升了 36%。它还将前 10 个应用程序中的 5 个应用程序的启动时间平均缩短了 33%,从而提高了工作效率,并在移动设备上提供了更流畅的用户体验。此外,根据 Speedometer 2.1 基准测试,它的网页浏览速度提高了 60%,并在包括光线追踪和可变速率着色 (VRS) 在内的七个图形基准测试中将峰值图形性能平均提高了 30% 。
与 Cortex-X4 相比,新的 Cortex-X925 平台在使用旨在加速现代 Arm CPU 上的 AI 应用的 KleidiAI 库时,在 LLaMA 3(80 亿个参数)中性能提升高达 42%,在 Phi 3(38 亿个参数)AI 模型中性能提升高达 46%。
从这次发布会我们可以看到,Arm选择在2024 年改进和完善其IP,而不是完全重新定义并做出突破性的改变。继去年推出 Armv9.2 系列内核之后,Arm 在 2024 年的最新 Cortex 系列架构中做出了一些显着改变,明确且有意转向更先进的 3 nm 工艺节点,三星和台积电 3 nm 均作为 2024 年平台基于客户端的 CSS 的基础。
Cortex-X925、Cortex-A725 和 Cortex-A520 内核已针对 3 nm 工艺进行了优化,显著提升了性能和能效。Cortex-X925 的解码和调度宽度增强了 10 倍,时钟速度提高到 3.8 GHz,有望为单线程 IPC 性能树立新标准。Arm 更新后的 v9.2 平台非常适合高性能应用,包括 AI 工作负载和高端游戏,无论是在移动领域还是在 Microsoft 的 Windows on Arm 生态系统中。
从总体来看,从 Arm 对新 CSS 平台和去年的 TCS2023 版本的内部性能比较来看,Arm 声称性能提升了 30% 到 60%,具体取决于任务和工作量。如果这是可信的,那么性能改进是令人难以置信的,而向 3 nm 的过渡可能是性能的主要改进因素,而不是底层架构的改进。
Cortex-A725 在性能和效率之间取得平衡,使其适用于多种中端设备。得益于增加缓存大小和扩展重新排序缓冲区等架构增强功能,Arm 声称这些改进比上一代产品实现了高达 35% 的性能效率。更新后的 Cortex-A520 主要侧重于在 3 nm 节点上进行优化,同时力求保持无与伦比的能效,与上一代产品相比,实现了 15% 的节能。该核心针对低强度工作负载进行了优化,使其成为物联网设备和低成本智能手机等对功耗敏感的应用的理想选择。
AI 功能一直是 Arm 最新产品的重要关注点。Cortex-X925 和 Cortex-A725 内核主要集成专用 AI 加速器,允许访问优化的软件库(例如 KleidiAI 和 KleidiCV),从而确保高效的 AI 处理。这些增强功能对于从神经语言模型到 LLM 等各种应用都至关重要。

Arm 还继续通过由新 CSS 平台驱动的、通常熟练且全面的生态系统支持其最新的核心集群,该生态系统与 Arm Performance Studio 以及 Kleidi AI 和 CV 库相结合。这些提供的工具为开发人员提供了充分利用新架构功能的强大基础。这有效地缩短了整体上市时间,并促进了各个行业的创新,例如内容创建和设备上的 AI 推理。CSS 平台与 Android、Linux 和 Windows(Arm 上的 Windows)等操作系统的集成确保了更大的采用范围。它推动了更广泛的开发水平,使软件和应用程序可以在比前几代更多的设备上使用。
总而言之,Arm 将其所有最新 CPU 设计都转向 3 nm 工艺技术,并对 Cortex-X925 和 Cortex-A725 内核进行改进,表明其战略重点是优化现有架构,而不是进行彻底的改变。这些改进包括增加每个内核的缓存大小、转向更宽的管道,以及为 2024 年增强 DSU-120 内核集群,这无疑在纸面上带来了显著的性能和能效提升。
在使新设备能够处理要求苛刻的应用程序的同时,这些效率和性能方面的改进大多是在转向更先进但更具挑战性的 3 纳米节点时实现的。随着 Arm 继续突破其 IP 的极限,这些技术应该为更强大、更高效、更智能的设备铺平道路,塑造移动设备未来的可能性和能力,无论是新一代支持 AI 的设备还是移动游戏,Arm 都希望提供这一切。
来源:半导体行业观察
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。