使用外部AI加速器,让i.MX处理器机器学习处理更给力!
恩智浦精心打造了i.MX应用处理器、i.MX RT跨界微控制器(MCU)产品组合和芯片系列,可满足广泛的市场需求。从需要极低功耗的垂直产品,到需要配有多个CPU、2D-3D GPU、DSP和NPU机器学习加速器的复杂异构计算平台的其他终端产品,我们的产品团队需要解决多维优化问题。最终目标是提供各种应用和产品所需的所有计算能力和连接,同时最大限度地减少未使用的功能,从而满足设备的占用空间面积、功耗和成本要求。
说到机器学习,有一些最终用途,例如自动驾驶车辆和自然语言处理,将边缘设备的计算要求推高到每秒数十万和数百万亿次运算(TOP)的高极限。随着业界日益重视开发专门面向边缘的高效的ML模型,并使用量化和修剪等技术,许多边缘机器学习应用适用于从Giga-Ops到较低的个位数TOPs的ML计算性能。恩智浦解决方案本身便可满足这大部分AI处理需求。
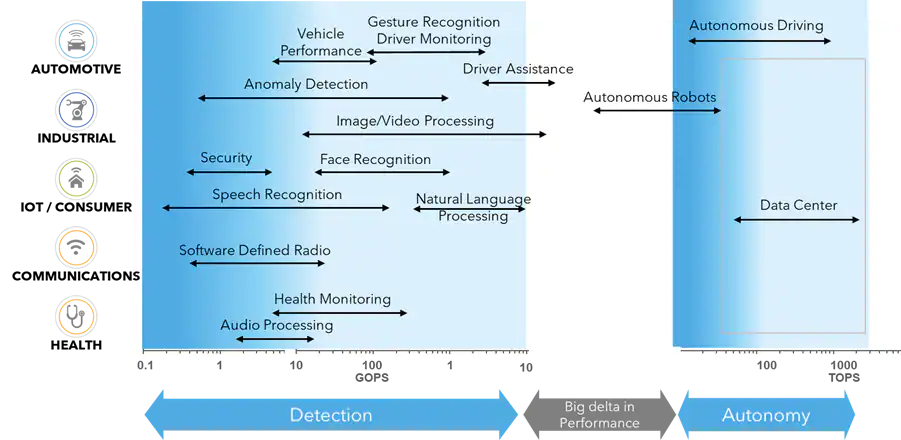
按细分市场划分的ML应用和 TOPs计算需求
如今,软件投资主导着硬件选择,在考虑产品路线图和多代产品时尤为如此。在开发一系列终端产品时,选择相同或类似的应用处理器显然有很大的优势,这样开发工作就可以转化为更高的成熟度和质量,还可以重复使用。不同的细分市场对应用的某些部分要求的性能不同,但不同版本和各级产品的基本功能保持不变。
可扩展的处理器系列(如i.MX应用处理器)使开发人员能够在各种高级功能和性能中灵活选择,同时还可提供通用的基本计算架构和功能集供产品组合中的成员使用,还提供通用的软件使能单元。恩智浦提供GStreamer和NNStreamer框架,通过ML简化视觉应用的部署。GStreamer被用作创建流媒体应用的框架,抽象出硬件层,允许使用任何i.MX SoC而无需改变底层的视觉pipeline软件。
即使产品在市场上推出后,应用要求和市场需求也会不断变化。那么,当您需要所选择的应用处理器提供更多功能时,您会怎么做?返回选择流程并寻找更高性能的处理器通常不是首选。在需要时添加另一个器件来提供额外的加速是可行的途径,特别是具有高速高带宽、低延迟的芯片到芯片连接选项(如PCIe)。恩智浦的生态体系合作伙伴通过专用的ML加速器芯片助您一臂之力。
Kinara是恩智浦的一个生态体系合作伙伴,开发面向专用ML加速的Ara-1 Edge AI处理器。恩智浦提供基于Gstreamer和NNStreamer的视觉pipeline支持,Kinara开发了Gstreamer兼容插件集,在这两者的加持下,可无缝地将Ara-1集成到恩智浦推理pipeline,并且还能够在功能需求改变时轻松地将设计迁移到不同的i.MX应用处理器。
Kinara和恩智浦如何协作提升嵌入式平台的AI性能,使其超越原生功能?了解详情,请阅读白皮书>>
将恩智浦i.MX应用处理器的原生ML处理能力与恩智浦生态体系合作伙伴(如Kinara)提供的专用ML加速器相结合,在恩智浦原有可扩展性的基础上进一步提高,同时仍然可以使用相同的软件。
本文作者
Ali Ors,恩智浦半导体边缘处理AI机器学习战略技术主管。Ali专门负责领导跨职能团队,为机器学习和愿景处理领域提供创新产品和平台。他目前在恩智浦负责全球AI机器学习战略和技术。Ali曾在恩智浦汽车业务部负责ADAS和自主产品的AI战略、战略伙伴关系和平台设计。加入恩智浦之前,Ali是CogniVue公司的工程副总裁,负责开发视觉SoC解决方案和认知处理器IP内核。Ali持有加拿大渥太华卡尔顿大学的工程学学位。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。