
SVM 是机器学习领域的经典算法之一。如果将 SVM推广到神经网络,会发生什么呢?
支持向量机(Support Vector Machine,SVM)是大多数 AI 从业者比较熟悉的概念。它是一种在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM 训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM 模型将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。 除了进行线性分类之外,SVM 还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。 本文将介绍一篇来自蒙特利尔大学的论文《SVM、Wasserstein 距离、梯度惩罚 GAN 之间的联系》。在这篇论文中,研究者阐述了如何从同一框架中得到 SVM 和梯度惩罚 GAN。 据论文一作介绍,这项研究的灵感来自她的博士资格考试。在准备过程中,她学习了 SVM,并思考了这个问题:「如果将 SVM 推广到神经网络会发生什么?」顺着这个思路,研究者发现了 SVM、GAN、Wasserstein 距离之间的关系。

该研究将最大间隔分类器(MMC)的概念扩展到任意范数和非线性函数。支持向量机是 MMC 的一个特例。研究者发现,MMC 可以形式化为积分概率度量(Integral Probability Metrics,IPM)或具备某种形式梯度范数惩罚的分类器。这表明它与梯度惩罚 GAN 有直接关联。 该研究表明,Wasserstein GAN、标准 GAN、最小二乘 GAN 和具备梯度惩罚的 Hinge GAN 中的判别器都是 MMC,并解释了 GAN 中最大化间隔的作用。研究者假设 L^∞ 范数惩罚和 Hinge 损失生成的 GAN 优于 L^2 范数惩罚生成的 GAN,并通过实验进行了验证。此外,该研究还导出了 Relativistic paired (Rp) 和 average (Ra) GAN 的间隔。 这篇论文共包含几部分:在第二章中,研究者回顾了 SVM 和 GAN;第三章,研究者概述了最大间隔分类器(MMC)的概念;第四章,研究者用梯度惩罚解释了 MMC 和 GAN 之间的联系。其中 4.1 提到了强制 1-Lipschitz 等价于假设一个有界梯度,这意味着 Wasserstein 距离可以用 MMC 公式来近似估算;4.2 描述了在 GAN 中使用 MMC 的好处;4.3 假定 L1 范数间隔能够导致更具鲁棒性的分类器;4.4 推导了 Relativistic paired GAN 和 Relativistic average GAN 的间隔。最后,第五章提供了实验结果以支持文章假设。 SVM 是 MMC 的一个特例。MMC 是使间隔最大化的分类器 f(间隔指的是决策边界与数据点之间的距离)。决策边界是指我们无法分辨出样本类别的区域(所有 x 使得 f(x)=0)。 Soft-SVM 是一种特殊情况,它可以使最小 L2 范数间隔最大化。下图展示了实际使用中的 Soft-SVM:
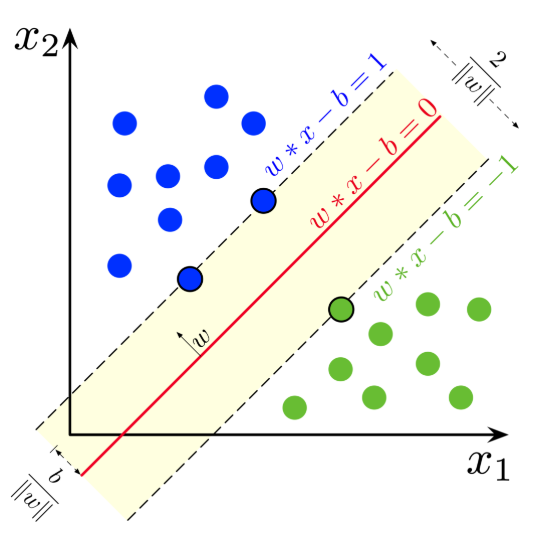
在解释这一结果之前,我们需要了解一个关键要素。关于「间隔」有多种定义: (1)样本与边界之间的最小距离; (2)距边界最近的点与边界之间的最小距离。 定义(2)更为常用。但是如果使用此定义,那么 SVM 文献中所谓的「函数间隔(functional margin)」和「几何间隔(geometric margin)」就都不能被视为间隔。这可能会让人十分困惑。 理解这种差异更好的一种方式是:
将(1)视为「样本的间隔」;
将(2)视为「数据集的间隔」。
但是,为了消除这两种情况的歧义,本文将前者称为「间隔(margin)」,将后者称为「最小间隔(minimum margin)」。 Hard-SVM(原始形式)解决了最大化最小间隔的问题。Soft-SVM 解决了另一个更简单的问题——最大化期望 soft-margin(最小化期望 Hinge 损失)。这个问题很容易解决,hinge 损失确保远离边界的样本不会对假重复 Hard-SVM 效果的尝试产生任何影响。 从这个角度看,最大化期望间隔(而不是最大化最小间隔)仍会导致最大间隔分类器,但是分类器可能会受到远离边界的点的影响(如果不使用 Hinge 损失的话)。因此,最大化期望间隔意味着最大化任何样本(即数据点)与决策边界之间的平均距离。这些方法就是最大间隔分类器(MMC)的示例。 为了尽可能地通用化,该研究设计了一个框架来导出 MMC 的损失函数。研究者观察到,该框架可以导出带有梯度惩罚的基于间隔的目标函数(目标函数 F 的形式为 F(yf(x)))。这就意味着标准 GAN、最小二乘 GAN、WGAN 或 HingeGAN-GP 都是 MMC。所有这些方法(和 WGAN-GP 一样使用 L2 梯度规范惩罚时)都能最大化期望 L2 范数间隔。 研究者还展示了,使用 Lipschitz-1 判别器的大多数 GAN(谱归一化 HingeGAN、WGAN、WGAN-GP 等)都可被表示为 MMC,因为假定 1-Lipschitz 等效于假定有界梯度(因此可作为一种梯度惩罚形式)。 重要的是,这意味着我们可以将最成功的 GAN(BigGAN、StyleGAN)看作 MMC。假定 Lipschitz-1 判别器一直被看作实现优秀 GAN 的关键因素,但它可能需要一个能够最大化间隔的判别器和相对判别器(Relativistic Discriminator)。该研究基于 MMC 判别器给伪生成样本带来更多梯度信号的事实,阐述了其优点。 在这一点上,读者可能有疑问:「是不是某些间距比其它间距更好?是的话,我们能做出更好的 GAN 吗?」 这两个问题的答案都是肯定的。最小化 L1 范数的损失函数比最小化 L2 范数的损失函数对异常值更具鲁棒性。基于这一事实,研究者提出质疑:L1 范数间隔会带来鲁棒性更强的分类器,生成的 GAN 也可能比 L2 范数间隔更佳。 重要的是,L1 范数间隔会造成 L∞ 梯度范数惩罚,L2 范数间隔会造成 L2 梯度范数惩罚。该研究进行了一些实验,表明 L∞ 梯度范数惩罚(因使用 L1 间隔产生)得到的 GAN 性能更优。 此外,实验表明, HingeGAN-GP 通常优于 WGAN-GP(这是说得通的,因为 hinge 损失对远离边界的异常值具有鲁棒性),并且仅惩罚大于 1 的梯度范数效果更好(而不是像 WGAN-GP 一样,使所有的梯度范数逼近 1)。因此,尽管这是一项理论研究,但研究者发现了一些对改进 GAN 非常有用的想法。 使用该框架,研究者能够为 Relativistic paired (Rp) GAN 和 Relativistic average (Ra) GAN 定义决策边界和间隔。人们常常想知道为什么 RpGAN 的性能不如 RaGAN,在这篇文章中,研究者对此进行了阐述。 使用 L1 范数间隔的想法只是冰山一角,该框架还能通过更具鲁棒性的间隔,设计出更优秀的 GAN(从而提供更好的梯度惩罚或「光谱」归一化技术)。最后,对于为什么梯度惩罚或 1-Lipschitz 对不估计 Wasserstein 距离的 GAN 有效
 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂