ARM Cortex-A32 – 复杂嵌入式设备的必然选择

架构对比
本文引用地址://www.cghlg.com/article/201608/295852.htmM 主要特性
ARM Cortex-M处理器基于ARMv7-M架构(Cortex-M0和Cortex-M0+ 采用类似的ARMv6-M架构)。虽然与早期的ARM架构有众多相似之处,但ARMv7-M经过专门打造,更适合深度嵌入、低成本的实时微处理器应用。因此,早期架构的很多功能被删除,并添加了新的特性,以构建更符合“微控制器”环境的编程模式。
对比前代处理器(例如备受欢迎的ARM7TDMI),变化具体如下:
• 操作模式数量显著减少,从7种甚至更多减至2种:仅保留处理器模式与线程模式。其中一种模式(处理器模式)可以默认为优先采用。
• 寄存器文件简化。虽然编程器可用的寄存器数量实质上仍然是16个,但前代架构使用的分组寄存器机制明显减少,因此两种操作模式寄存的只有栈指针(r13)。是否使用寄存拷贝可自行设置。
• 异常模式的变化最为明显。由于典型的微控制器应用可能会出现大量的芯片外设中断,基于此,全新架构中的所有Cortex-M核心都配置了标准嵌套中断向量控制器(Nested Vectored Interrupt Controller,NVIC)。类似的,根据记载处理器地址的向量表,异常处理模式也被标准化。上下文保存和恢复操作完全在硬件中实现,进一步简化编写中断处理器的软件任务。基于上述,实现过程中的干扰性延迟发生几率被降到极低,且高度可预测。
• 与前代ARM处理器类似,ARMv7-M定义了可选内存保护架构。同时,因为裸金属系统或在实时操作系统(RTOS)下运行的系统通常不需要虚拟内存,ARMv7-M并不为其提供支持。
• 为协助实时操作系统(RTOS)的实现和移植,一些标准的片上外围设备也在架构中获得定义,例如SysTick timer。
• 为进一步缩小处理器核心面积,ARMv7-M处理器仅采用Thumb指令集(包括Thumb-2指令集扩展)。
ARMv8-A AArch32 主要特性
Cortex-A处理器基于ARMv7-A或ARMv8-A架构。ARMv8-A处理器支持AArch32执行态,是32位ARMv7-A架构的兼容升级。这些架构的设计添加了专属特性,比如虚拟内存环境,以支持包括Linux、Android、Windows等的平台操作系统。
对比Cortex-M处理器核心,Cortex-A独特之处包括:
• 拥有7种或更多操作模式:用户、管理器、IRQ、FIQ、未定义、中止、系统。每种模式都可以处理一项具体事件,例如,IRQ模式被用于处理IRQ中断。AArch32还支持另外两种模式:Hyp 和监视器,这两种模式分别用于虚拟化及ARM TrustZone。
• 虽然可以使用的寄存器数量同样是16个,但AArch32有许多与上述操作模式相对应的“分组”(banked)寄存器。一旦进入特定操作模式,这些寄存器就会取代对应的用户模式。这使异常处理的许多方面得到简化,但也意味着需要提高机器管理能力,并在初始化上花更大的功夫。
• 异常模式有显著差别,与最初的ARM架构设备一脉相承。具体来说,向量表是由一组可执行的指令组成,而不是地址,并且保存和恢复上下文的任务几乎完全由编程器承担。
• 还有一个重要差别是内存管理单元(Memory Management Unit ,MMU),内存管理单元会编译核心提交的虚拟地址以及存储系统需要的物理地址。针对Linux一样的平台操作系统所使用的完整需求分页虚拟存储器环境,Cortex-A也可以提供支持。
ARMv7-M 与 AArch32 的不同之处
从基于Cortex-M处理器的系统迁移到基于Cortex-A32处理器的系统时,许多新特性也有必要了解。
尽管这两种架构之间有许多相似之处(如寄存器组和指令集存在多种共性),但仍然需要清楚一点,ARMv8-A架构在AArch32执行态下的许多特性是基于早期架构的。
本节将详细介绍AArch32的特性。这些特性在ARMv7-M中不具备,或者实现方式极其不同。
操作模式
如图3所示,ARMv7-M仅定义两种操作模式,线程模式与处理器模式。处理器模式可以设置为普通模式,也就是说,在不需要时,软件可以不启用该特性。处理器模式主要被用于处理异常情况,线性模式则用于用户进程。模式间的转化基本上是自动的,发生条件如图所示。如异常情况发生,处理器模式自动启用,异常处理完成后,处理器模式自动退出。SVCall指令是软件进入处理器模式的主要方法(将启动的IRQ设定为未决,可令处理器执行异常操作)。
对比图4,图3显示的是AArch32执行态下支持的操作模式。基本的操作模式有七种,其中五种用于处理特定异常。如发生快速中断(Fast Interrupt,FIQ)异常,则会进入FIQ模式;如出现未定义指令,则进入Undef模式,诸如此类。
模式间的转换通常自动执行,但是如果在现程序状态寄存器(Current Program Status Register,CPSR)中写入模式字段,则可完全由软件控制进行模式转换,具体细节稍后再做说明。与SVCall指令类似,SVC指令可以支持软件处理SVC异常,并进入SVC模式。
AArch32还支持其他两种模式,但未在图中显示(仅为节省版面空间)。它们分别是Hyp模式(用于管理程序)和监控模式(用于TrustZone)。由于内容复杂,本文件暂不涉及。
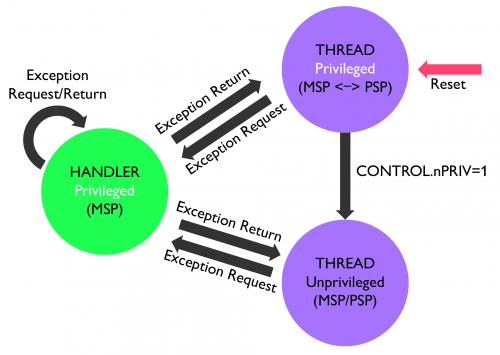
图3- ARMv7-M操作模式
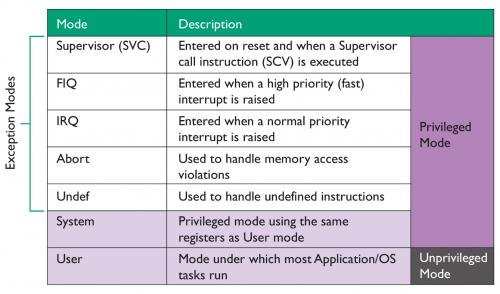
图4- AArch32操作模式
寄存器组
图5及图6分别介绍了ARMv7-M 和 AArch32寄存器组。
从图中可以看出,两种寄存器有许多相似之处,这是因为两者皆承袭了ARMv6及早期架构的共同特性。
多数指令可以访问13个通用寄存器(r0至r12)。两种架构下,r13预设为栈指针(SP),r14预设为连接寄存器(LR),r15预设为程序计数器(PC)。ARMv7-M架构下,访问专用寄存器受到严格限制;AArch32下,可以用与其他通用寄存器相同的方式访问这些寄存器;不过无需多言,擅自修改PC值可能会产生不良后果!
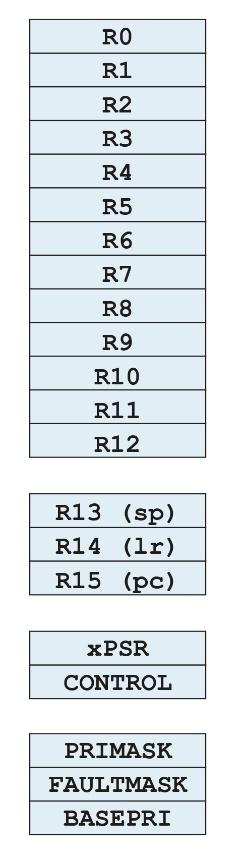
图5- ARMv7-M寄存器组
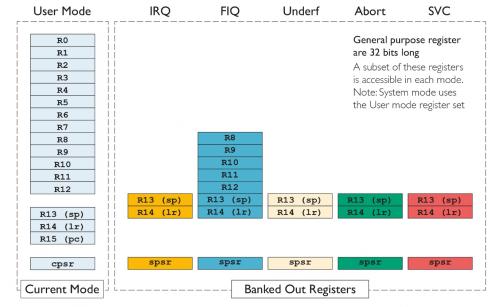
图6- AArch32寄存器组
ARMv7-M是一小组其他专用寄存器,包括PRIMASK、FAULTMASK、xPSR、CONTROL及BASEPRI,用于控制、配置处理器及处理异常情况。
指令集
如图6所示,AArch32还有一些与特定操作模式相关的寄存器。如进入对应的模式下,这些寄存器会与相应的用户模式切换。只有极少数特殊指令能够访问,并且还无法直接访问。这些数值随着模式变化被保存,以辅助异常处理。特别值得指出的是,每种异常模式都对应独立的栈指针,从而能够在单独堆栈上解决每个异常状况。这就让异常处理程序更可靠、防御性更强。异常出现后,相关模式的连接寄存器会被设定为异常返回地址。
如图所示,每种异常模式都对应一个附加寄存器,即程序保护状态寄存器(SPSR)。程序保护状态寄存器用于出现异常时及时记录当前的程序状态寄存器数值以及LR,从而自动保存相关数据。
另外,AArch32的图示中未显示Mon与Hyp模式。与其他模式一样,它们分别支持R13与R14分组寄存器。
Cortex-A架构下,有一个与ARM NEON SIMD指令集相关的独立寄存器组(如下),包含32个128位宽寄存器。每个寄存器都可作为单字、双字或四倍字寻址,NEON指令集也支持依据字节或四倍字进行向量运算。
异常模型
上述两个架构的异常模型具有显著差异,但两者都支持因系统事件或外围中断引起的内部及外部异常。
ARMv7-M支持与传统微控制器上发现的异常更相近的模型,所有外部中断都通过含有处理器地址的向量表单独进行向量处理。
AArch32与早期ARM架构中的异常模型更相近,早期的ARM架构中仅有8种异常类型,向量也各不相同。向量表由可执行指令组成,通常是特定异常处理器的分支指令。仅支持两种外部中断源,即FIQ和IRQ。通常,一个高优先级中断会连接FIQ,其他则连接IRQ。这意味着系统要么装有软件调度程序,要么就要和现代系统一样装有中断向量控制器(Vectored Interrupt Controller,VIC),可以利用单一向量地址进行编程。
多数Cortex-A系统装有基于ARM的通用中断控制器(Generic Interrupt Controller,GIC)。GIC是许多物理中断和ARM核心中断输入(FIQ和IRQ)的接口,处理优先次序、遮蔽、单一中断启用或禁止,及优先权。欲了解更多信息,请参考《GIC架构参考手册》。
指令集
自25年前ARM1的诞生起,ARM指令集便不断演变。Cortex-A处理器实际支持两个指令集,每个指令集都有各自的扩展。
ARM指令集
ARM指令集基于首款ARM处理器支持的原始指令集。该指令集已经过了数次扩展。简而言之,这是一个负载-存储指令集,拥有不同指令组,主要用于数据处理、存储访问、系统控制和控制流程。现代的ARM指令集非常强大,适用范围非常广泛。在指令集内,所有指令被编码为32位固定长度的字,并且必须与字边界一致。
Thumb指令集
Thumb指令集是ARM指令集的子集,其中每个指令被编码为16位半字,并且必须与半字边界一致。Thumb指令集最初的依据是,在编译高级语言(如C语言)时,减小最常用的指令的大小,从而提高代码密度。由于指令越小,会有更多指令可以汇集在给定的高速缓存,对运行指令的高速缓存就越有利。
高级SIMD扩展
高级SIMD扩展也被称为NEON,是一组庞大的指令集,通过扩充寄存器集实现SIMD向量处理能力。
向量浮点(VFP)
VFP指令集实用与NEON的相同的寄存器分组,是符合IEEE-754单、双精度浮点的运算指令。
Thumb-2技术
Thumb-2是一个扩展集的总称,起初为ARMv6T2(第一款,使用ARM1156T2-S处理器)的Thumb指令集。由此生成一个混合长度指令集,同时具备Thumb的高代码密度和ARM指令集的高性能和高灵活性。
如果使用过Cortex-M微控制器,您一定会对Thumb-2非常熟悉。在最小(Cortex-M0和Cortex-M0+)到最大(Cortex-M7中)的各种子集中,核心仅支持Thumb-2。你会发现,使用Cortex-A处理器可以生成更多的代码。
一般来说,为Cortex-A编译的大部分高级代码都是针对Thumb(及Thumb-2)的。这使编译器能够在最大程度上做出明智的判断,从多种选择中选取需要的指令,并实现代码空间编译和性能编译之间的差异最大化。
ARM指令集通常被用于代码段,性能至关重要。有时,这些代码段需要通过手工在汇编器上编码,ARM指令集也因此成为最佳选择。
NEON指令集可通过多种方式访问:
• 支持常用数学、分析函数和算法的库。
• 编译器可以为多种内在函数集提供支持,允许直接使用C语言访问几乎整个NEON指令集。通过这种方法,可以用最简便的方式将NEON操作插入C语言。
• 可以直接在汇编器上手工实现NEON。
• 编译器还支持迭代循环的自动向量化。将代码写入一些简单指令,编译器会非常有效地展开极其复杂的循环,并进行向量化。
如果对ARMv7-A处理器很熟悉,您还会注意到作为ARMv8-A也在使用的一些其它指令。
加密扩展
这些是ARMv8-A中的新指令,运行在NEON寄存器组,旨在有效地执行密码函数的算法。
负载获取和存储释放(Load Acquire and Store Release)
这些新指令匹配C++11访存排序语义,编译非常高效。它们还可用于降低对数据端内存屏障的需求,部分消除与其有关的能耗支出。
另外,还有其它一些浮点和屏障指令的扩展。
虚拟内存支持
支持完全虚拟内存环境是ARMv8-A的一个主要特性,使设备可以支持Linux和Android等平台操作系统。同样,虚拟内存能力通常也是客户选择核心的重要依据。
虚拟内存环境使操作系统能够以更加灵活的方式管理内存,例如,允许单独处理动态扩展栈区域,按照需求将单个代码和数据区域调入和调出外部存储页面,并使每个用户处理系统内存映射的相同视图。
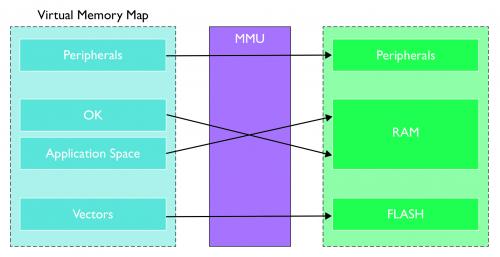
图7-虚拟内存
为此,如图7所示,虚拟内存在处理器提供的每个地址上进行“转换”。软件在“虚拟地址空间”和称为内存管理单元(Memory Management Unit,MMU)的模块中运行,并将其转换为“物理地址空间”,为系统中的每个用户任务以及操作系统本身创建新的虚拟内存映射,还使操作系统完全控制访问权限等。每项任务都可以在自身的虚拟内存空间中执行,就像是系统中的唯一任务。只有操作系统知道外部物理内存中该任务的代码和数据区域的真实物理位置。
任务切换时,操作系统的其中一项工作就是重新配置MMU,使代码和数据能被输入任务使用,同时让输出任务的存储器可以暂时访问。这进一步增强了任务之间的分离,构建安全可靠的系统。
这里我们不再深入研究所有细节。简而言之,ARM处理器的MMU使用了“页面表”(外部存储器中)的数据,驱动并控制转换。系统已经经过一系列优化(如转换查找缓冲器(TLBs),缓存通过转换降低读取页面表的功耗),让转换过程的功耗降到最低。
软件从 ARMv7-M 移植到 ARMv7-A
大多数高级软件在移植前需要经过重新编译。需要注意以下方面:
• 重置代码和其他异常处理程序
如果使用操作系统,那么操作系统提供会进行处理;多数情况下,可以通过公共域分布或设备供应商获取操作系统的端口。
由于异常模式的显著差异,中断处理器需要重写。此外,操作系统会提供完成这项任务应遵循的基础结构,从而完成中断处理器主体的重新编译。
• 外围驱动器
如果从RTOS转移到例如Linux的平台操作系统,应用程序代码和外围驱动器需要严格划分。
• 系统配置功能
基于Cortex-M 和Cortex-A的设备访问系统配置和控制功能的方式具有明显差异。Cortex-M处理器通常通过已命名或内存映射的寄存器进行配置,这些寄存器可以直接读取和写入。Cortex-A处理器(Cortex-A32支持的AArch32执行态)则通过“系统控制协处理器”得以实现。“协处理器15”配有大型配置寄存器组,这些寄存器大量使用专用指令读取或写入(参考说明文件中的MRC 和 MCR)。操作系统未执行的系统配置功能将需要重新写入。也就是说,操作系统通常会向用户软件提供API的访问功能。
• 汇编码
对于汇编码,我们需要仔细留意。写入汇编码的一个重要原因是实现性能最大化,所以要严格检查,确保重写后扩展指令集访问性能得到提升,NEON就是一个例子。如果已经用“统一汇编语言”语法(UAL)写入了旧的汇编码,那么就需要将大部分内容重新汇编为ARM或Thumb指令。






评论