基于BP网络的字母识别

3.3.3 再次用理想样本训练
在网络进行了上述的训练以后,网络对无误差的信号可能也会采用对带有噪声信号的办法。这样做会付出较大的代价。因此,必须再次使用理想的样本进行训练。这样就可以保证在输入理想数字信号时,网络能够最好地对其做出反应。其训练代码如下:
netn.trainParam.goal=0.00001;
netn.trainParam.epochs=1000;
netn.trainParam.show=5;
[netn,tr]=train(netn,p,t);
训练结果为:
TRAINLM, Epoch 0/1000, SSE 4.60127e-007/1e-005, Gradient 4.23932e-006/1e-010
TRAINLM, Performance goal met.
满足要求。
3.4 对网络进行仿真和测试
为了测试系统的可靠性,本文用了加入不同级别的噪声的字母样本作为输入,来观察用理想样本和加噪样本训练出来的网络的性能,并绘制出误识率曲线,如图5所示。
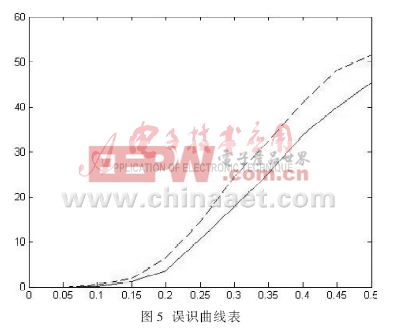
图5其中虚线代表用无噪声训练网络的出错率,实线代表用有噪声训练网络的出错率。从图5可以看出,在均值为0~0.05之间的噪声环境下,两个网络都能够准确地进行识别。当所加的噪声均值超过0.05时,待识别字符在噪声作用下不再接近于理想字符,无噪声训练网络的出错率急剧上升,此时有噪声训练网络的性能较优。
3.5 测试实例
本文用一个含噪声的字母F作为网络输入,并绘出含噪声的字母F,其输出语句为:
noisyF=alphabet(:,6)+randn(35,1)*0.2;plotchar(noisyF) ;
其结果如图6所示。












评论